Langfuse で LLM 評価を効率化!活用方法徹底解説
- Yuto Toya
- 2025年2月5日
- 読了時間: 6分

更新日:2025年4月10日
1.初めに
近年、AI 技術、特に大規模言語モデル(LLM)の進化は目覚ましく、様々な分野での活用が進んでいます。しかし、LLM をビジネスに適用する上で、その品質をどのように評価するかが大きな課題となっています。
これまでの LLM の評価は、主に「出力結果の目視確認」や「ユーザーフィードバック」に頼ってきました。この従来のアプローチには、以下のような課題があります
評価基準の曖昧さ
何をもって良い評価とするのかが評価者によって異なり、客観的な評価が困難
個人の価値観や経験によって、評価結果にばらつきが生じます
評価の多面性
正確性、簡潔性、論理的構成など、複数の観点からの評価が必要で
多角的な視点での評価が必要となり、総合的な判断が難しくなります
実装の複雑さ
テストデータの準備、評価項目の設定、結果の可視化など、多くの実装工程が必要
評価用データセットの作成やプロンプトの作成に多くの工数がかかります
このような課題を解決し、効率的かつ効果的な LLM 評価を実現するために、注目されているのが Langfuse です。 Langfuse は、LLM システムの開発から運用までをサポートする包括的なプラットフォームです。本記事では、特に LLM の評価機能に焦点を当て、Langfuse がどのように LLM 開発を効率化するのか、具体的な活用方法を解説します。
2. Langfuseによる評価機能
Langfuse は、これらの課題を解決するために、以下の2つの主要な評価機能を備えています。※セルフホスティングの場合はPro/Enterprise版を利用する必要あり
Human Annotate: 人間の手によるラベル付けを可能にします。開発者以外のドメインエキスパートが評価する場合に特に有効です。
LLM as a Judge: LLM を評価者として活用し、評価用プロンプトに基づいて自動で評価を行います。これにより、評価の客観性と効率性を高めることができます。
Langfuse の評価機能を利用することで、評価軸を明確に定義し、客観的な評価を行うことが容易になります。また、評価結果は UI 上で可視化され、トレースと紐付けられるため、問題点を特定しやすく、効率的な改善サイクルを実現できます。
3. RAGASとLangfuseの評価アプローチの違い
RAGシステムの評価フレームワークとして、RAGASは広く使用されています。RAGASは汎用的な評価フレームワークとして、検索精度や応答の関連性など、RAGシステムの基本的な性能を測定するために設計されています。しかし、実際のビジネス応用においては、以下のような制約があります
RAGASの制約
事前に定義された評価指標に基づく標準的な評価
ドメイン固有の要件への対応が限定的
評価基準の詳細な調整が困難
これに対し、Langfuseは実務での活用に焦点を当てた評価プラットフォームとして、以下のような特徴があります
Langfuseの特徴
ドメイン固有の評価基準を柔軟に設定可能
評価プロンプトのカスタマイズと継続的な改善
具体的な評価例
金融分野での規制要件への適合性評価
医療分野での専門用語の正確性評価
このように、RAGASとLangfuseはそれぞれ異なる用途に適しています。RAGASはRAGシステムの基本性能を標準的に評価する際に有効で、Langfuseは実際のビジネス要件に応じた詳細な評価が必要な場合に適しています。
RAGASとLangfuseの主な違い
RAGAS | Langfuse | |
プロンプトを作成する必要性 | 必要なし | 必要あり 各評価用のテンプレートはある |
評価用プロンプトの可視化 | Githubから確認 | LangfuseのUI上で確認 |
評価のカスタマイズ性 | ほぼなし | 評価基準を作成・修正が容易に可能 |
実装方法 | ソースコードで実装 | UIで設定(別途実装も可能)
|
日本語での評価制度 (個人的印象) | 不安定 | 安定するように評価用プロンプトの修正が可能 |
Langfuse を用いた評価の実践
データセットの作成
Langfuse では、トレースデータから評価用データセットを簡単に作成できます。UI 上で必要なトレースを選択し、「Add to dataset」ボタンをクリックするだけで、データセットとして利用できます。

また、データセット用のトレースをあらかじめ作成しておけば、より柔軟なデータセット作成が可能です。ユーザの入力だけ取得をして、データセットとして保管しておきたい場合などに有用です。
方法としては以下のような、関数を1つ作成するだけです。
例:(ユーザの入力だけほしい場合)
## python
@observe()
async def trace_dataset():
langfuse_context.update_current_observation(input=ユーザの入力 ,output="")テストデータセットの選定と管理
Langfuse では、作成したデータセットを「Queue」という仕組みで管理します。トレースを Annotation の Queue に入れ、ドメインエキスパートが Queue を仕分けることで、適切なテストデータを選定できます。これにより、評価に必要なデータだけを効率的に管理し、テストの精度を高めることができます。

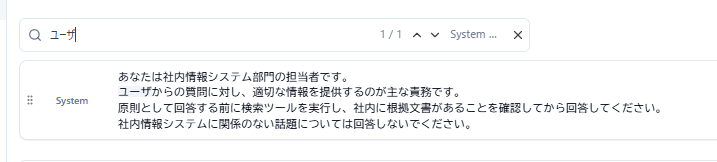
トレースからqueueに入れる画面

Human Annotateの画面(仕分け画面)
LLM as a Judge の利用方法
Langfuse の LLM as a Judge 機能を利用すると、データセットの選定も効率的に行えます。あらかじめ LLM as a Judge の設定をしておけば、トレースには自動でスコアが入力されるため、怪しい値をチェックすることで、より精度の高いデータセットを選定できます。


テスト実行と結果の可視化
選定したデータセットを用いて、Langfuse 上でテストを実行します。テストの際には、モデルやプロンプトを自由に選択でき、複数の評価基準を設定することも可能です。テスト結果は、ダッシュボードで可視化され、各データポイントの評価スコア、入出力、トレースなどの情報を一目で確認できます。これにより、システムの改善点を効率的に特定し、迅速な改善サイクルを回すことが可能です。

Langfuseを活用した評価サイクル
以上の機能を用いることで以下のような評価・改善サイクルが実現できます。
LLMの出力結果をトレースし、Langfuseで可視化
Annotation の Queueに入れて、ドメインエキスパートの人に出力結果を判断してもらう & LLM as a Judgeで各評価項目に対してスコアを出力させる
2で悪い結果の原因追及をして、入力をデータセットに格納(オプションで期待する出力もあると良い)
プロンプトを変更する
プロンプト実験を行い、前回のプロンプトの出力との違いについてLangfuse上で結果を可視化し原因の追求
5. まとめ
Langfuse は、LLM システムの開発から運用までをカバーする包括的なプラットフォームです。特に評価機能においては、以下のような作業を UI 上で完結させることができます。
評価の事前準備
評価用プロンプトの作成
評価基準の定義
ドメイン固有の要件への対応
テストの効率化
トレースからの自動データセット作成
Human AnnotateとLLM as a Judgeの併用
複数の評価軸でのテスト実行
結果の可視化と改善
定量的なスコア表示
トレースを活用した原因追求
プロンプト実験による継続的な改善
現状では、Langfuseはトレースやモニタリング機能の利用がメインとなっていますが、本記事で紹介した評価機能を活用することで、LLM開発のライフサイクル全体を効率的に管理することが可能です。評価から改善までのサイクルを一つのプラットフォームで完結できる点は、開発効率を大きく向上させる要因となるでしょう。
ぜひ Langfuse を導入し、効率的なLLM開発の実現を目指してみてください。


コメント