Langfuse Trace詳細画面における特殊レンダリングパターンガイド
- Shunsaku Takagi
- 1月27日
- 読了時間: 8分

更新日:2月2日
本記事では、LangfuseのTrace詳細画面で利用できる主要な特殊レンダリングパターンを解説します。これらのパターンを活用することで、トレース情報をより視覚的かつ構造的に表示できます。
対象読者
LangfuseでLLMアプリケーションのトレースを取得している開発者
Langfuseのトレースのアナリスト・手動評価者
はじめに
複雑になるトレース構造
近年のLLMは多機能化・高性能化が進み、1つのトレースに様々な情報を詰め込むことが一般的になってきました。画像認識、音声処理、ツール呼び出し、推論過程など、単純なテキスト入出力だけでは済まないケースが増えています。
しかし、情報量が増えれば増えるほど、本来可視化を目的としているはずのトレース画面が逆に見にくくなってしまう、という問題が発生します。大量のJSON文字列が羅列されるだけでは、重要な情報を見逃したり、デバッグに時間がかかったりします。
そこで役立つのが、Langfuseが提供する特殊レンダリング機能です。適切なJSON構造を使うことで、同じデータをより整理された形で表示でき、開発効率が大きく向上します。
特殊レンダリングが用意されている理由
Langfuseのトレースは、OpenAI、Anthropic、Geminiといった主要なLLMプロバイダーのレスポンススキーマに対応しています。各プロバイダーが採用している独自のJSON構造を自動的に認識し、適切な形式で画面表示するため、開発者はプロバイダー固有のフォーマットをそのまま記録できます。
以降では、実際にどのようなJSON構造が特殊なレンダリング対象となるのか、主要4パターンを見ていきます。
パターン1: ChatML形式の会話履歴
ChatML(Chat Markup Language)は、LLMとの会話履歴を構造化して記録する標準的な形式です。Langfuseは複数のChatML記述方法に対応しています。
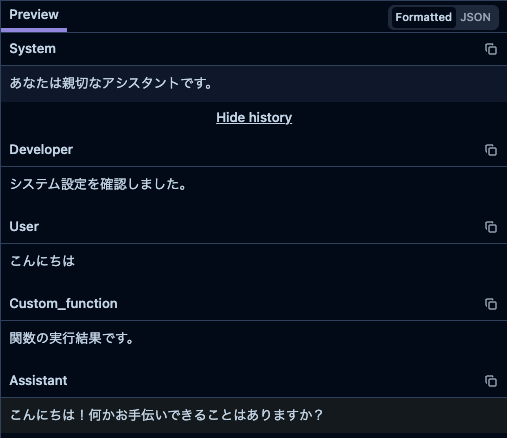
基本構造
配列の各要素がroleとcontentキーを持つオブジェクトであれば、自動的にChatML形式として認識されます。
[
{"role": "user", "content": "こんにちは"},
{"role": "assistant", "content": "こんにちは!何かお手伝いできることはありますか?"}
]対応するroleと表示
画面上では、roleに応じて異なるラベルと背景色が適用されます。
user: "User"と表示
assistant: "Assistant"と表示(アクセント背景色で区別)
system: "System"と表示(アクセント背景色で区別)
tool: "Tool"と表示
function: "Function"と表示
developer: "Developer"と表示
カスタム表示名
nameフィールドを追加すると、roleではなくそちらが優先表示されます。
{
"role": "assistant",
"name": "AI Agent Alpha",
"content": "処理を開始します"
}この場合、画面には"AI Agent Alpha"と表示されます。
ラッパー形式
以下のような構造にも対応しています。
{
"messages": [
{"role": "user", "content": "質問です"}
]
}ネストされた配列形式も認識されます。
[[{"role": "user", "content": "質問です"}]]パターン2: ツール定義と実行結果
Function CallingやTool Useと呼ばれる機能を使う際、Langfuseはツールのスキーマ定義と実行ログを視覚的に表示します。

ツールスキーマの定義
メッセージにtoolsフィールドを追加すると、画面上部に「Tools」セクションが表示されます。
{
"role": "user",
"content": "東京の天気を調べて",
"tools": [
{
"name": "get_weather",
"description": "指定した都市の天気情報を取得します",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "都市名"}
},
"required": ["city"]
}
}
]
}ツールの呼び出し記録
アシスタントがツールを呼び出した際の記録は、tool_callsフィールドで表現します。
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_abc123",
"name": "get_weather",
"arguments": "{\"city\": \"東京\"}"
}
]
}画面上では、メッセージ内にTool Invocationカードが表示されます。
ツールからの返答
ツール実行結果は、role: "tool"のメッセージとして記録します。
{
"role": "tool",
"tool_call_id": "call_abc123",
"content": "{\"temperature\": 22, \"condition\": \"晴れ\"}"
}OpenAI形式のネスト構造
OpenAIのChat Completions APIで使われるネスト構造にも対応しています。
{
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"city\": \"東京\"}"
}
}
]
}パターン3: マルチモーダルコンテンツ
マルチモーダルファイルのアップロード方法や全般的な使い方については、こちらの記事で詳しく解説されていますので、そちらをご参照ください。
ここでは、特殊レンダリングに必要なJSON構造について解説します。
基本構造
マルチモーダルコンテンツとして認識されるには、contentが配列で、各要素にtypeキーが必要です。
{
"role": "user",
"content": [
{"type": "text", "text": "この画像について教えて"},
{"type": "image_url", "image_url": {"url": "https://example.com/image.png"}}
]
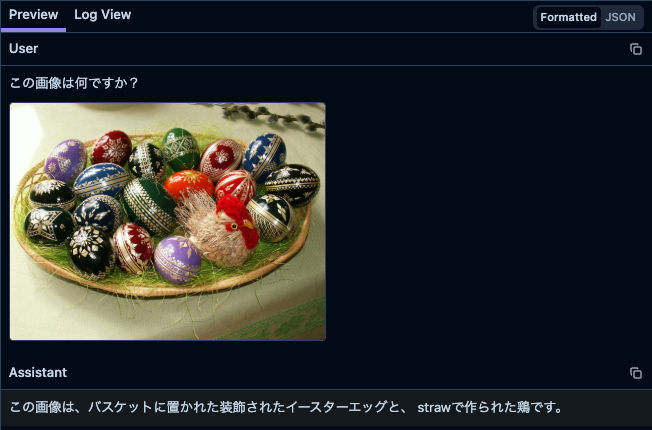
}画像の表示(type: "image_url")
画像を表示するには、以下のような構造を使います。
{
"role": "user",
"content": [
{"type": "text", "text": "この画像を説明して"},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png",
}
}
]
}対応しているURL形式
形式 | 例 |
HTTP/HTTPS URL | https://example.com/image.png |
Base64 Data URI | data:image/png;base64,iVBORw0KGgo... |
Langfuseメディアトークン | @@@langfuseMedia:type=image/jpeg|id=<uuid>|source=base64@@@ |
対応している画像形式: PNG, JPEG, JPG, GIF, WebP
画面上では、画像が実際に表示され、クリックでリサイズ可能です。
音声入力(type: "input_audio")
音声データを入力として記録する場合は、以下の構造を使います。
{
"role": "user",
"content": [
{
"type": "input_audio",
"input_audio": {
"data": "@@@langfuseMedia:type=audio/mp3|id=<uuid>|source=base64@@@"
}
}
]
}音声データは、Langfuseメディア参照形式で記録します。画面上ではオーディオプレーヤーが表示されます。
音声出力(audioフィールド)
アシスタントが音声で返答した場合は、メッセージにaudioフィールドを追加します。
{
"role": "assistant",
"content": "音声でお答えします",
"audio": {
"data": "@@@langfuseMedia:type=audio/mp3|id=<uuid>|source=base64@@@",
"transcript": "これは音声の文字起こしです。"
}
}画面には、文字起こしテキストとオーディオプレーヤーが両方表示されます。

その他のファイル(PDF等)
Langfuseメディアトークンを使うことで、PDFなど任意のファイルタイプも添付できます。
@@@langfuseMedia:type=application/pdf|id=<uuid>|source=base64@@@画面上では、ファイルアイコンと表示リンクが表示されます。

パターン4: 推論過程(Thinking Block)
一部のLLMは、最終的な回答を生成する前の推論過程を出力します。Langfuseはこれを折りたたみ可能な「Thinking」ブロックとして表示します。この特殊レンダリングはv3.148.0から搭載されています。
標準形式(Anthropic形式)
{
"role": "assistant",
"content": "答えは4です。",
"thinking": [
{
"type": "thinking",
"content": "これは基本的な算数問題です。2+2=4と計算しました。",
"summary": "計算結果は4"
}
]
}summaryは省略可能です。

リダクテッド形式(暗号化された推論内容)
Anthropic APIでは、推論内容が暗号化されて返される場合があります。
{
"role": "assistant",
"content": "回答内容",
"redacted_thinking": [
{
"type": "redacted_thinking",
"data": "<encrypted blob>"
}
]
}OpenAI Responses API形式(自動変換)
OpenAIの新しいResponses APIでは、推論が別メッセージとしてoutput配列内に記録されます。Langfuseはこれを自動的にthinkingフィールドへ変換します。
{
"output": [
{
"type": "reasoning",
"content": [{"type": "text", "text": "計算を行っています..."}],
"summary": [{"type": "text", "text": "結果は4"}]
},
{
"role": "assistant",
"content": "4です。"
}
]
}Gemini形式(自動変換)
Gemini APIでは、thought: trueというフラグで推論部分を示します。
{
"parts": [
{"text": "計算中...", "thought": true},
{"text": "4です。"}
]
}この形式も内部的にthinkingフィールドへ変換され、画面上で折りたたみ可能なブロックとして表示されます。
よくある間違いとトラブルシューティング
間違い1: roleの指定ミス
ChatML形式では、roleとcontentの両方が必要です。どちらか一方だけでは認識されません。
{"content": "こんにちは"} // 認識されない
{"role": "user", "content": "こんにちは"} // 正しい間違い2: MediaURIをどこかに入れれば自動レンダリングされると思い込む
Langfuseの公式ドキュメントを読むと、「MediaURIをtraceのどこかに入れれば、いい感じにレンダリングされる」という印象を受けるかもしれません。
しかし、実際には指定されたJSON形式に従わないとレンダリングされません。例えば、以下のような単純な文字列として埋め込んでも、画像として表示されません。
{
"role": "user",
"content": "@@@langfuseMedia:type=image/jpeg|id=xxx|source=base64@@@"
}
正しくは、マルチモーダルコンテンツの構造に従う必要があります。
{
"role": "user",
"content": [
{"type": "text", "text": "画像の説明"},
{
"type": "image_url",
"image_url": {
"url": "@@@langfuseMedia:type=image/jpeg|id=xxx|source=base64@@@"
}
}
]
}今後への期待
これらの特殊レンダリング機能は非常に便利ですが、改善の余地もあります。
特にマルチモーダルファイルの添付については、もっと柔軟な仕様にしてほしいというのが個人的な願いです。現状では、前述の通り厳密なJSON構造に従わないとレンダリングされませんが、MediaURIをinput、output、metadataのどこかに含めるだけで自動的に認識されるような仕組みになれば、開発者の負担が大きく軽減されるでしょう。
公式ドキュメントの記述からは「どこに入れても大丈夫」という印象を受けますが、実際には構造化が必要です。この点が改善されることを期待しています。
まとめ
LLMアプリケーションの開発において、トレース情報の可視化は非常に重要です。情報量が増えれば増えるほど、適切な構造化と表示方法が求められます。
本記事で紹介したLangfuseの特殊レンダリングパターンを活用することで、以下のメリットが得られます。
複雑なトレース情報が整理され、一目で理解できるようになる
デバッグ時に重要な情報へ素早くアクセスできる
チーム内でのトレース共有がスムーズになる
主要LLMプロバイダーのレスポンス形式をそのまま記録できる
ただし、本記事で紹介したように、指定のJSON構造でないと特殊レンダリングされません。この点には注意してください。
今後、Langfuseがさらに柔軟なレンダリング機能を提供してくれることを期待しつつ、今あるレンダリングの仕様を最大限活用して、より効率的なLLM開発を進めていきましょう。

コメント